LumenWorksCsvReader2 4.3.0
See the version list below for details.
dotnet add package LumenWorksCsvReader2 --version 4.3.0
NuGet\Install-Package LumenWorksCsvReader2 -Version 4.3.0
<PackageReference Include="LumenWorksCsvReader2" Version="4.3.0" />
paket add LumenWorksCsvReader2 --version 4.3.0
#r "nuget: LumenWorksCsvReader2, 4.3.0"
// Install LumenWorksCsvReader2 as a Cake Addin #addin nuget:?package=LumenWorksCsvReader2&version=4.3.0 // Install LumenWorksCsvReader2 as a Cake Tool #tool nuget:?package=LumenWorksCsvReader2&version=4.3.0
CSV Reader
The CsvReader library is an extended version of Sébastien Lorion's fast CSV Reader project and provides fast parsing and reading of CSV files

To this end it is a straight drop-in replacement for the existing NuGet package LumenWork.Framework.IO and LumenWorksCsvReader, but with additional capabilities; the other rationale for the project is that the code is not available elsewhere in a public source repository, making it difficult to extend/contribute to.
Welcome to contributions from anyone.
You can see the version history here.
Build the project
- Install Fake
- In the command line run dotnet fake build
Library License
The library is available under the MIT License, for more information see the License file in the GitHub repository.
Getting Started
A good starting point is to look at Sébastien's article on Code Project.
A basic use of the reader something like this...
using System.IO;
using LumenWorks.Framework.IO.Csv;
void ReadCsv()
{
// open the file "data.csv" which is a CSV file with headers
using (var csv = new CachedCsvReader(new StreamReader("data.csv"), true))
{
// Field headers will automatically be used as column names
myDataGrid.DataSource = csv;
}
}
Having said that, there are some extensions built into this version of the library that it is worth mentioning.
Additional Features
Columns
One addition is the addition of a Column list which holds the names and types of the data in the CSV file. If there are no headers present, we default the column names to Column1, Column2 etc; this can be overridden by setting the DefaultColumnHeader property e.g.
using System.IO;
using LumenWorks.Framework.IO.Csv;
void ReadCsv()
{
// open the file "data.csv" which is a CSV file with headers
using (var csv = new CachedCsvReader(new StreamReader("data.csv"), false))
{
csv.DefaultColumnHeader = "Fred"
// Field headers will now be Fred1, Fred2, etc
myDataGrid.DataSource = csv;
}
}
You can specify the columns yourself if there are none, and also specify the expected type; this is especially important when using against SqlBulkCopy which we will come back to later.
using System.IO;
using LumenWorks.Framework.IO.Csv;
void ReadCsv()
{
// open the file "data.csv" which is a CSV file with headers
using (var csv = new CachedCsvReader(new StreamReader("data.csv"), false))
{
csv.Columns.Add(new Column { Name = "PriceDate", Type = typeof(DateTime) });
csv.Columns.Add(new Column { Name = "OpenPrice", Type = typeof(decimal) });
csv.Columns.Add(new Column { Name = "HighPrice", Type = typeof(decimal) });
csv.Columns.Add(new Column { Name = "LowPrice", Type = typeof(decimal) });
csv.Columns.Add(new Column { Name = "ClosePrice", Type = typeof(decimal) });
csv.Columns.Add(new Column { Name = "Volume", Type = typeof(int) });
// Field headers will now be picked from the Columns collection
myDataGrid.DataSource = csv;
}
}
SQL Bulk Copy
One use of CSV Reader is to have a nice .NET way of using SQL Bulk Copy (SBC) rather than bcp for bulk loading of data into SQL Server.
A couple of issues arise when using SBC 1. SBC wants the data presented as the correct type rather than as string 2. You need to map between the table destination columns and the CSV if the order does not match exactly
Below is a example using the Columns collection to set up the correct metadata for SBC
public void Import(string fileName, string connectionString)
{
using (var reader = new CsvReader(new StreamReader(fileName), false))
{
reader.Columns = new List<LumenWorks.Framework.IO.Csv.Column>
{
new LumenWorks.Framework.IO.Csv.Column { Name = "PriceDate", Type = typeof(DateTime) },
new LumenWorks.Framework.IO.Csv.Column { Name = "OpenPrice", Type = typeof(decimal) },
new LumenWorks.Framework.IO.Csv.Column { Name = "HighPrice", Type = typeof(decimal) },
new LumenWorks.Framework.IO.Csv.Column { Name = "LowPrice", Type = typeof(decimal) },
new LumenWorks.Framework.IO.Csv.Column { Name = "ClosePrice", Type = typeof(decimal) },
new LumenWorks.Framework.IO.Csv.Column { Name = "Volume", Type = typeof(int) },
new LumenWorks.Framework.IO.Csv.Column { Name = "IsActive", Type = typeof(bool) },
};
// With the help of CustomBooleanReplacer you can define a mapping between string values in the CSV file and boolean values
// In this example, 'Y' and 'Yes' will be treated as true; 'N' and 'No' - as false value.
reader.CustomBooleanReplacer = new Dictionary<string, bool>
{
{"Y", true},
{"N", false},
{"Yes", true},
{"No", false},
};
// Now use SQL Bulk Copy to move the data
using (var sbc = new SqlBulkCopy(connectionString))
{
sbc.DestinationTableName = "dbo.DailyPrice";
sbc.BatchSize = 1000;
sbc.AddColumnMapping("PriceDate", "PriceDate");
sbc.AddColumnMapping("OpenPrice", "OpenPrice");
sbc.AddColumnMapping("HighPrice", "HighPrice");
sbc.AddColumnMapping("LowPrice", "LowPrice");
sbc.AddColumnMapping("ClosePrice", "ClosePrice");
sbc.AddColumnMapping("Volume", "Volume");
sbc.AddColumnMapping("IsActive", "IsActive");
sbc.WriteToServer(reader);
}
}
}
The method AddColumnMapping is an extension I wrote to simplify adding mappings to SBC
public static class SqlBulkCopyExtensions
{
public static SqlBulkCopyColumnMapping AddColumnMapping(this SqlBulkCopy sbc, int sourceColumnOrdinal, int targetColumnOrdinal)
{
var map = new SqlBulkCopyColumnMapping(sourceColumnOrdinal, targetColumnOrdinal);
sbc.ColumnMappings.Add(map);
return map;
}
public static SqlBulkCopyColumnMapping AddColumnMapping(this SqlBulkCopy sbc, string sourceColumn, string targetColumn)
{
var map = new SqlBulkCopyColumnMapping(sourceColumn, targetColumn);
sbc.ColumnMappings.Add(map);
return map;
}
}
One other issue recently arose where we wanted to use SBC but some of the data was not in the file itself, but metadata that needed to be included on every row. The solution was to amend the CSV reader and Columns collection to allow default values to be provided that are not in the data.
The additional columns should be added at the end of the Columns collection to avoid interfering with the parsing, see the amended example below...
public void Import(string fileName, string connectionString)
{
using (var reader = new CsvReader(new StreamReader(fileName), false))
{
reader.Columns = new List<LumenWorks.Framework.IO.Csv.Column>
{
...
new LumenWorks.Framework.IO.Csv.Column { Name = "Volume", Type = typeof(int) },
// NB Fake column so bulk import works
new LumenWorks.Framework.IO.Csv.Column { Name = "Ticker", Type = typeof(string) },
};
// Fix up the column defaults with the values we need
reader.UseColumnDefaults = true;
reader.Columns[reader.GetFieldIndex("Ticker")] = Path.GetFileNameWithoutExtension(fileName);
// Now use SQL Bulk Copy to move the data
using (var sbc = new SqlBulkCopy(connectionString))
{
...
sbc.AddColumnMapping("Ticker", "Ticker");
sbc.WriteToServer(reader);
}
}
}
VirtualColumns
It may happen that your database table where you would like to import a CSV contains more or different columns than your CSV file. As SqlBulkCopy requires to define all column mappings from the target table, you can use the VirtualColumns functionality:
csv.VirtualColumns.Add(new Column { Name = "SourceTypeId", Type = typeof(int), DefaultValue = "1", NumberStyles = NumberStyles.Integer });
csv.VirtualColumns.Add(new Column { Name = "DataBatchId", Type = typeof(int), DefaultValue = dataBatchId.ToString(), NumberStyles = NumberStyles.Integer });
In this case you define 2 additional columns that do not exist in the source CSV file, but exist in the target table. Also you can set the DefaultValue that will be bulk-copied to the target table together with the CSV file content. Do not forget to include the defined virtual columns to the SqlBulkCopy column mapping!
ExcludeFilter
In case if your CSV file is big enough and you do not want to import a whole file but some set of data, you can set the ExcludeFilter action:
csv.ExcludeFilter = () => ((csv["Fmly"] ?? "") + (csv["Group"] ?? "") + (csv["Type"] ?? "")).ToUpperInvariant() == "EQDEQUIT";
In this case all rows that fit the defined criteria will not be imported to the database.
Performance
To give an idea of performance, this took a naive sample app using an ORM from 2m 27s to 1.37s using SBC and the full import took just over 11m to import 9.8m records.
One of the main reasons for using this library is its excellent performance on reading/parsing raw data, here's a recent run of the benchmark (which is in the source)
| Test | .NET 4.7.2 | .NET 4.8 | .NET Core 3.1 | .NET 5 | .NET 6 |
|---|---|---|---|---|---|
| Test pass #1 - All fields | |||||
| CsvReader - No cache | 18.029 | 17.4115 | 18.6588 | 20.9881 | 19.8229 |
| CachedCsvReader - Run 1 | 15.8878 | 15.6856 | 16.4155 | 19.478 | 19.2338 |
| CachedCsvReader - Run 2 | 103700.2121 | 100227.7904 | 119402.9851 | 102923.9766 | 119532.7357 |
| TextFieldParser | 10.6325 | 10.7448 | 11.3845 | 13.3976 | 13.4799 |
| Regex | 11.0006 | 11.2566 | 11.603 | 16.8422 | 16.6653 |
| Test pass #1 - Field #72 (middle) | |||||
| CsvReader - No cache | 33.8842 | 34.4039 | 34.5182 | 48.3443 | 47.2414 |
| CachedCsvReader - Run 1 | 20.0675 | 20.0483 | 21.5359 | 24.4861 | 24.2664 |
| CachedCsvReader - Run 2 | 1647940.075 | 1325301.205 | 1050119.332 | 1148825.065 | 1170212.766 |
| TextFieldParser | 10.5588 | 10.8054 | 11.5507 | 13.6496 | 13.9692 |
| Regex | 23.8385 | 24.2478 | 25.6357 | 40.7933 | 40.2386 |
| Test pass #2 - All fields | |||||
| CsvReader - No cache | 23.7762 | 24.7155 | 24.7757 | 29.4928 | 29.2318 |
| CachedCsvReader - Run 1 | 15.4433 | 15.4299 | 16.2404 | 19.0609 | 18.7912 |
| CachedCsvReader - Run 2 | 1325301.205 | 1506849.315 | 1100000 | 1242937.853 | 1428571.429 |
| TextFieldParser | 9.4764 | 10.7936 | 11.583 | 13.7241 | 14.1607 |
| Regex | 9.8131 | 11.3284 | 11.8905 | 17.1912 | 17.816 |
| Test pass #2 - Field #72 (middle) | |||||
| CsvReader - No cache | 34.8114 | 34.8461 | 35.5218 | 49.8421 | 49.2037 |
| CachedCsvReader - Run 1 | 20.719 | 20.7746 | 21.8001 | 25.8437 | 25.2911 |
| CachedCsvReader - Run 2 | 1317365.27 | 1264367.816 | 1002277.904 | 1242937.853 | 1225626.741 |
| TextFieldParser | 10.3391 | 10.5819 | 11.5539 | 13.5875 | 14.1446 |
| Regex | 23.8867 | 23.6028 | 25.0774 | 41.7542 | 40.7904 |
| Test pass #3 - All fields | |||||
| CsvReader - No cache | 24.5748 | 24.0699 | 24.4865 | 29.4968 | 29.041 |
| CachedCsvReader - Run 1 | 14.6422 | 14.7653 | 16.7683 | 20.3806 | 18.0145 |
| CachedCsvReader - Run 2 | 1379310.345 | 1383647.799 | 1006864.989 | 1173333.333 | 1157894.737 |
| TextFieldParser | 10.7302 | 10.6394 | 11.5478 | 13.5921 | 14.2006 |
| Regex | 11.0881 | 11.0249 | 11.4958 | 17.9792 | 17.6474 |
| Test pass #3 - Field #72 (middle) | |||||
| CsvReader - No cache | 34.4315 | 35.0067 | 34.5559 | 50.7796 | 49.0471 |
| CachedCsvReader - Run 1 | 17.3084 | 19.1313 | 17.2032 | 21.462 | 23.9831 |
| CachedCsvReader - Run 2 | 1442622.951 | 1428571.429 | 1047619.048 | 1242937.853 | 1192411.924 |
| TextFieldParser | 10.7142 | 10.5523 | 11.5291 | 13.7035 | 14.1779 |
| Regex | 23.3738 | 23.7406 | 25.1373 | 41.8325 | 41.2974 |
| Average of all test passes | .NET 4.7.2 | .NET 4.8 | .NET Core 3.1 | .NET 5 | .NET 6 |
|---|---|---|---|---|---|
| CsvReader - No cache | 28.2512 | 28.4089 | 28.7528 | 38.1573 | 37.2647 |
| CachedCsvReader - Run 1 | 17.3447 | 17.6392 | 18.3272 | 21.7852 | 21.5967 |
| CachedCsvReader - Run 2 | 1.202.706.6762 | 1.168.160.8923 | 887.714.0429 | 1.025.649.3224 | 1.049.041.7220 |
| TextFieldParser | 10.4085 | 10.6862 | 11.5248 | 13.6091 | 14.0222 |
| Regex | 17.1668 | 17.5335 | 18.4733 | 29.3988 | 29.0759 |
As you can see, an average performance slightly increases from full .NET Framework 4.7.2 to .NET Core 6.
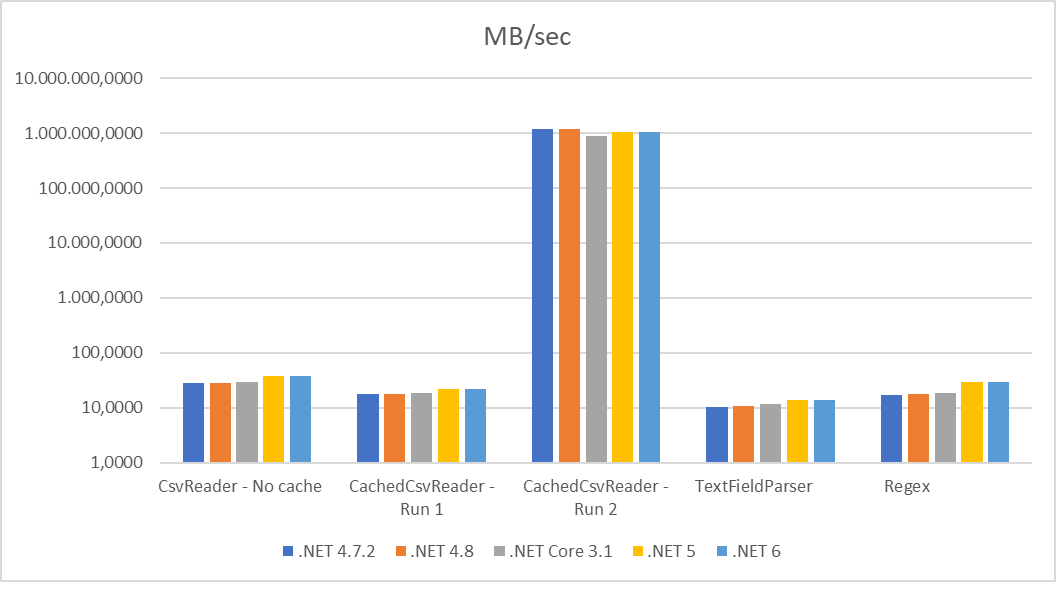 This was run on a Core i5-8400 (6 cores), 32Gb RAM and 2Tb SSD.
This was run on a Core i5-8400 (6 cores), 32Gb RAM and 2Tb SSD.
| Product | Versions Compatible and additional computed target framework versions. |
|---|---|
| .NET | net5.0 is compatible. net5.0-windows was computed. net6.0 is compatible. net6.0-android was computed. net6.0-ios was computed. net6.0-maccatalyst was computed. net6.0-macos was computed. net6.0-tvos was computed. net6.0-windows was computed. net7.0 was computed. net7.0-android was computed. net7.0-ios was computed. net7.0-maccatalyst was computed. net7.0-macos was computed. net7.0-tvos was computed. net7.0-windows was computed. net8.0 was computed. net8.0-android was computed. net8.0-browser was computed. net8.0-ios was computed. net8.0-maccatalyst was computed. net8.0-macos was computed. net8.0-tvos was computed. net8.0-windows was computed. |
| .NET Core | netcoreapp2.0 was computed. netcoreapp2.1 was computed. netcoreapp2.2 was computed. netcoreapp3.0 was computed. netcoreapp3.1 is compatible. |
| .NET Standard | netstandard2.0 is compatible. netstandard2.1 was computed. |
| .NET Framework | net461 was computed. net462 was computed. net463 was computed. net47 was computed. net471 was computed. net472 is compatible. net48 is compatible. net481 was computed. |
| MonoAndroid | monoandroid was computed. |
| MonoMac | monomac was computed. |
| MonoTouch | monotouch was computed. |
| Tizen | tizen40 was computed. tizen60 was computed. |
| Xamarin.iOS | xamarinios was computed. |
| Xamarin.Mac | xamarinmac was computed. |
| Xamarin.TVOS | xamarintvos was computed. |
| Xamarin.WatchOS | xamarinwatchos was computed. |
-
.NETCoreApp 3.1
- No dependencies.
-
.NETFramework 4.7.2
- No dependencies.
-
.NETFramework 4.8
- No dependencies.
-
.NETStandard 2.0
- NETStandard.Library (>= 2.0.3)
-
net5.0
- No dependencies.
-
net6.0
- No dependencies.
NuGet packages (3)
Showing the top 3 NuGet packages that depend on LumenWorksCsvReader2:
| Package | Downloads |
|---|---|
|
GnossApiWrapper.NetCore
Gnoss Api Wrapper, for using the Gnoss API. |
|
|
GnossApiWrapper
Gnoss Api Wrapper, for using the Gnoss API. |
|
|
FishbowlConnector.Net.Json
Package for interacting with the Fishbowl Connector API from a .NET project using JSON. |
GitHub repositories (1)
Showing the top 1 popular GitHub repositories that depend on LumenWorksCsvReader2:
| Repository | Stars |
|---|---|
|
RaythaHQ/raytha
Raytha is a powerful CMS with an easy-to-use interface and fast performance. It offers custom content types, a template engine, and various access controls. It supports multiple storage providers and an automatically generated REST API. Upgrade your development workflow with Raytha.
|
Fixed a crash when a developer wants to see the content of the Columns property during debugging
Added CustomBooleanReplacer to define a mapping for boolean values